Table of Contents
Kinesis
Kinesis vs Kafka
| Kinesis | Kafka | |
|---|---|---|
| Deployment types | May use 2 modes: – Provisioned mode – On-demand mode (new) – capacity is adjusted on demand; default capacity is 4MB/sec, maximum 200MB/s write and 400MB/s per consumer read | |
| Retention | 1-365 days | Unlimited |
| Stream | Topic | |
| Shard | Partition | |
| Record partition key | Record key | |
| Record data | Record data | |
| ApproximateArrivalTimestamp | Timestamp ? | |
| Shard id (string) | Partition number (number) | |
| Sequence number (meaningless number) | Offset (per partition sequential (usually, but not a rule) number) | |
| Messages order | Preserved ar shard level | Preserved at partition level |
| Compression | No | Available |
| Encryption at rest | KMS | KMS for MSK / No encryption in non-AWS deployments |
| Encryption in flight | TLS | TLS or PLAINTEXT |
| Security | IAM policies | For MSK: – Mutual TLS & Kafka ACLs – SASL/SCRAM & Kafka ACLs – IAM Access Control (Access control in IAM includes not only IAM policies but also other elements like roles, identity providers, authentication mechanisms, and service-specific permissions) |
| Producer rate | 1MB/sec per shard | ? |
| Message size | Hard limit for producer is 1MB | Default 1MB messages – may be increased |
| Consumption limits | – 2MB/sec shared for all the consumers – 2MB/sec per consumer in enhanced mode (with a default limit of 20 consumers per data stream by default) | |
| Consumer groups available? | Only for KCL consumers | Yes |
| Checkpoint feature for KCL consumers | Offset submitting for a consumer group | |
| For checkpoint feature uses DynamoDB (thus need to make sure you have enough writing capacity (WCU) or throttling exceptions (ExpiredIteratorException) may be encountered – may be leveraged by using on-demand DynamoDB write capacity) | Consumer group offsets are saved in a dedicated topic – no external dependencies | |
| Consumption from | shard.iterator.type (TRIM_HORIZON) | auto.offset.reset (earliest, latest) |
| Availability | Is deployed in a region | |
| “Splitting” shard (split operation). Old shard is closed and the data will be deleted once the data is expiredIs useful when 1MB/s/shard/producer is not enough – you need faster producing capabilitiesIs useful when you have hot shards – potentially you can get granulated and less hot shards | Add partition | |
| Merging shardsGroup shards with low trafficOld shards are closed and deleted based on data retention configuration | NO reducing partitions count available | |
| Auto scaling | No real auto-scaling – some UpdateShardCount operation, but not real auto-scaling. | No horizontal auto-scaling. Even in Confluent (the clusters have pre-defined processing power defined in Confluent units for Kafka – CKUs) |
| De-duplication | NO build-in de-duplication mechanism. | Idempotent producing is available (producer config) |
| Its working “instances” are called delivery streams. | Kafka clusters |
Kinesis SDK
Has 2 APIs:
- PutRecord
- PutRecords
May causeProvisionedThroughtputExceededexception! – need to check you don’t have a hot partition. Solution: Retries with backof, Increase shards (scaling), use a good partition key so that you don’t end up with hot shards.
Best for low throughput. Good for lambdas ? (need to check on this)
Kinesis KPL
Has automation for retries! ✅
Sends metrics to CloudWatch.
Lacks compression functionality ❌ – needs to be implemented by the user.
Has:
- Synchronous API
- Asynchronous API
Implements batching
- collects records in a single PutRecords API call.
- Also can aggregate records – combining multiple records in a single one (actual single messages rather than collecting during a timeframe for a batch)
Default batching time is set by RecordMaxBufferTime and is of 100ms. An additional delay may be set by RecordMaxBufferTime. But this adds latency.
Overall KPL is easier to use but adds latency because of batching.
Kan produce both to Kinesis and Firehose?
Kinesis Agent
It is for logs only and for Linux based systems only.
May send data to:
- Kinesis Data Streams
- Kinesis Data Firehose
May have 2 parallel flows configured: for ex. one for Firehose and another one for Data Streams
Can perform some format conversions: ex. CSV to JSON
Kinesis Consumer SDK
Max 2MB per all consumers per shard in standard mode.
You need to specify from which shard you’re reading!
- Get stream description
- Get shard iterator for a specific shard
- Send a GetRecords
- Receive:
- An array of records
- SequenceNumber
- ApproximateArrivalTimestamp
- Data
- PartitionKey
- NextShardIterator
- MillisBehindLatest (? is this the consumer lag ?)
- Use the NextShardIterator in next GetRecords
Standard mode – polling of records.
GetRecords
- returns max 10MB of data or 10k records (throttling happening because of the 2MB limit and this causes the response to come in 5 seconds)
- max of 5 GetRecords per shard per second!
- the more consumers you have the less throughput you’ll have per consumer: 5 consumers requesting in 1 second results in 400kB per consumer per second max.
Kinesis Client Library (KCL)
When used with a KPL producer de-aggregation can be leveraged – that function of combining multiple small messages in a single one of max 1MB.
No matter how many consumers you have, in enhanced fan out mode, each consumer will receive 2MB per second of throughput and have an average latency of 70ms.
DynamoDB is used for checkpointing functionality and if DynamoDB is under provisioned, checkpointing does not happen fast enough and results in low consumption throughput. Need to make sure to increase the RCU / WCU of DynamoDB.
.No need to specify the shard to consume from!
Kinesis Connector Library
Runs on a EC2
Kind of deprecated and replaced by these:
- Lambdas
- Kinesis Firehose
Lambda consumption off Kinesis Data Streams
Lambda consumer has the de-aggregation functionality just as KCL
Lambda has some ETL functionality
Has configurable batch size
Kinesis Enhanced Fan Out
Each consumer gets 2MB/s/shard (rather than 2MB/all consumers/sec/shard)
When used, you subscribe to a shard – Kinesis starts pushing data over HTTP/2 to the consumer (no polling anymore)
Latency ~70ms instead of ~200ms.
To be used when more than ~3 consumers and low latency requirements.
! Default limit is 20 enhanced fan-out consumers per data stream.
Re-sharding
During re-sharding consumer may receive the data out of order if there is no logic to first complete reading from the parent shard that was split. What happens is that you don’t finish consuming off parent and consume from children – but the producer “switched” producing to the child. So the child contains some later records in comparison to parent. Meaning that when you consume the children events you actually have skipped some records (that were in the parent). You may consume the records off parent later on but the order will be broken then.
When split is over the parent shard becomes closed for writes – so that is the moment when the producer starts producing to the child shards.
It is important to read entirely from the parent until there are no new incoming records on the parent shard – this will guarantee the consumer order of events is not affected by re-sharding.
KCL has this implemented! 😊
Re-sharding cannot be done in parallel – it is a synchronous series of actions. 1k shards re-sharding (split) take about 30k seconds to happen.
There are more limitations in place.
Duplicates in Kinesis
Producer retries can produce duplicates (because Kinesis Data Streams may fail to ack of record receive and same data would be sent by producer).
Consumer retries can also produce duplicates from consumer point of view – mainly because of
- re-sharding,
- worker terminating unexpectedly,
- workers being added or removed or
- application being deployed.
The solution is to perform uniqueness checks against some state storage.
Recommendation is to use a uniqueness key in the data part of the records – so no built-in mechanism available.
Kinesis Security
Access and authorization – IAM policies
Encryption in flight – HTTPS
Encryption at rest – KMS
VPC endpoints available to access it in VPC
NO client-side encryption
Kinesis Firehose
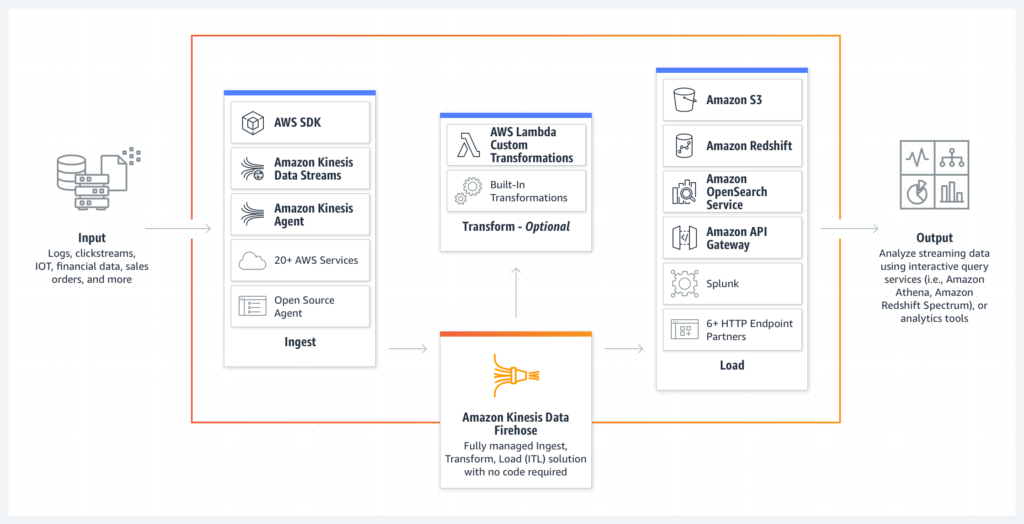
Fully SaaS
No data storage
Reads up to 1MB at a time
May add a lambda for data transformations (there are blueprint templates available) but also does supports some transformations on its own (ex. Parquet to ORC for S3 only)
Collects data in batches and writes those – for the batches there are time (60 sec. min) or size limit.
Important destinations:
- S3
- RedShift (through S3 by issuing a COPY command after data gets to S3)
- OpenSearch
- Splunk
May configure a S3 bucket to store:
- Delivery failed records
- Transformation failed records
- All source records
Supports auto-scaling + can automatically increase the buffer size to increase throughput.
Supports compression for S3 (GZip, Zip, Snappy) and Gzip for RedShift.
You pay only for usage – no provisioning required.
Its working “instances” are called delivery streams.
Spark Streaming can read from Kinesis Data Firehose.
CloudWatch
CloudWatch Logs Subscriptions Filters
Logs can be streamed to:
- Kinesis Data Streams
- Kinesis Data Firehose
- Lambdas
- SQS
SQS
- Fully managed
- Auto-scaling: from 1 to 15k messages/sec.
- Min retention is 1 minute, max retention time 14 days (4 days default)
- No limit on messages in queue
- No limit on transactions per second (TPS)
- Very fast: <10ms to publish or receive
- Horizontal scaling of consumers
- At least once delivery
- Order not guaranteed (for standard SQS)
- Max size per message – 256KB
- Is a good fit to be used as a buffer: for a DB or any other system with many incoming messages
- Can be integrated with Auto Scaling through CloudWatch
- SQS metrics > CouldWatch Alarm > Trigger Auto Scaling policy > Increase or decrease is triggered
- Maximum 120k in-flight messages
- Security:
- Encryption in flight – HTTPS
- Server Side Encryption (SSE) using KMS: we set the Customer Master Key and that is used for encrypting the body only (no message ID, attributes, timestamp)
- IAM is available
- Access policy is available
SQS Messages
- A message is composed of:
- Body – 256KB text: XML, JSON or plain text
- Attributes – [{name, type, value}]
- Delay delivery (optional)
- In response to sending a message:
- Message identifier
- MD5 of the body
SQS Consumers
- They poll messages (max batch size 10 messages of 256KB max.)
- Message should be processed within the visibility timeout
Amazon Simple Queue Service (SQS) is a fully managed message queuing service provided by Amazon Web Services (AWS). SQS visibility timeout is an important concept in SQS that helps manage the processing of messages by consumers (typically applications or services) in a distributed system.
Here’s an explanation of SQS visibility timeout:
- Message Visibility: When you send a message to an SQS queue, it goes into the queue and becomes available for processing by consumers. However, once a consumer retrieves a message from the queue, the message becomes temporarily invisible to other consumers. This is done to ensure that only one consumer processes the message.
- Visibility Timeout: The visibility timeout is the duration during which a message remains invisible after it has been successfully retrieved by a consumer. This timeout is specified when you retrieve a message from the queue, and it starts counting down as soon as the consumer receives the message.
- Message Processing Time: The consumer is expected to process the message within the visibility timeout duration. If the consumer successfully processes the message and deletes it from the queue within this time frame, everything is fine. The message is removed from the queue, and processing is complete.
- Handling Failures: If the consumer fails to process the message within the visibility timeout period, the message becomes visible again in the queue. It reverts to a state where it can be retrieved by another consumer. This ensures that the message is not lost in case of processing failures.
- Retry Mechanism: The visibility timeout serves as a built-in retry mechanism. If a consumer fails to process a message, it can simply wait for the message to become visible again and try processing it once more.
By setting an appropriate visibility timeout, you can control how long a message should remain invisible to other consumers in case of processing delays or failures. It allows you to handle scenarios where processing might take longer than expected without risking message loss or duplication. Keep in mind that you should choose an appropriate visibility timeout based on your application’s requirements and the expected processing time for messages. It’s an important parameter to consider when designing your SQS-based architecture to ensure the reliability and fault tolerance of your system.
- They delete the message using the Message identifier and receipt handle
The message ID is a globally unique identifier assigned to a message when it’s added to the queue and remains constant throughout the message’s lifetime. It’s typically used for tracking and auditing. On the other hand, the receipt handle is a unique token generated for a specific retrieval of a message and is used to acknowledge and delete messages during processing.
FIFO SQS Queue
- Messages are in order (so can be processed in order by the consumers)
- Lower throughput compared to standard SQS queue
- max 3k w/ batching and
- max 300 w/o batching
- During 5 minutes there is a de-duplication logic available – if a Duplication ID is being sent
SQS messages of more than 256KB
This is achievable using SQS Extended Library (Java).
It uses an AWS S3 bucket to store the actual body but the SQS message will contain only some metadata with a reference to the file stored in S3
DMS (Database Migration Service)
- Source database remains available.
- Supports both homogenous and heterogenous migrations – same or different database engines.
- Supports continuous replication using CDC (Change Data Capture)
Requires an EC2 instance to run on.
Sources and targets:
- On-premises/EC2 DB
- Oracle
- SQL
- MariaDB
- SAP
- DB2
- Azure
- Amazon
- RDS
- S3
- DocumentDB
For heterogenous migrations (with different DB engines) AWS Schema Conversion Tool (SCT) (deployed for ex. to an EC2) needs to be used to convert the schema from one to another.
Direct Connect (DX)
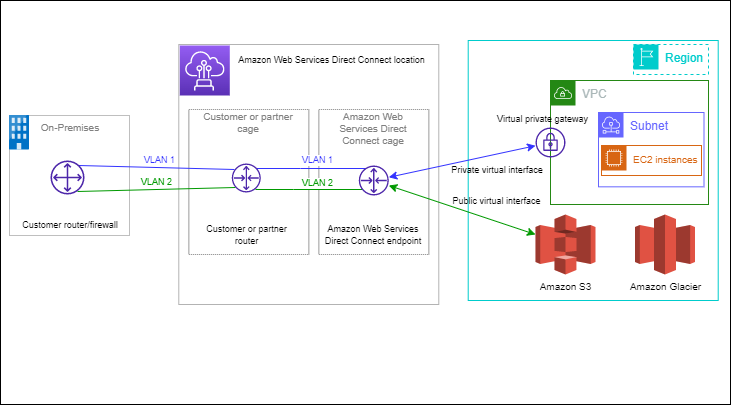
A dedicated private connection from a remove network to VPC. The connection is set up to a Direct Connect location. On the VPC side a Virtual Private Gateway is required to be set up. After that using single connection access is gained to both public and private resources.
Advantages:
- Fast
- More reliable
- Can combine on-premises with cloud environments resulting in hybrid environments
Connection types:
- Dedicated: using a physical ethernet port – 1/10/100 Gbps
- Hosted: via AWS Direct Connect Partners, capacity can be modified and can be chosen from 1/2/5/10 Gbps
Setting up the connection takes about 1 month.
Data is not encrypted! To have an IPsec-encrypted private connection AWS Direct Connect should be combined with a VPN.
DX Resiliency
- High Resiliency for Critical Workloads: one connection at multiple locations
- Maximum Resiliency for Critical Workloads: separate connections terminating on separate devices in more than one location
AWS Snow Family
These are devices used for:
- Collecting data
- Processing data at edge
- Migrating data in and out of AWS
Data migration
3 devices types:
- Snowmobile

Millions of TerraBytes – exabytes. Good fit for transfers of greater than 10 PB. - Snowball Edge

80 TB of HDD capacity - Snowcone

2.1kg. 8TB HHD or 14TB SSD. Can be used both online with AWS DataSync or offline. Good for scenarios of up to 24 TB migrations.



Ideal for huge amounts of data. May be a good fit for bad or even no connectivity. If a migration takes more than a week because of the connectivity – it may be better to use AWS Snow Family devices.
Edge computing
Processing data when it is created at an edge location (a location without connectivity). Data is being pre-processed/feed to machine learning or transcoded (video) at the edge location.
2 devices types that can run EC2 instances or Lambda functions:
- Snowball Edge
- Compute optimized:
42TB HDDs or 28TB NVMe. 104vCPUs, 416 GB RAM, optional GPU. Clustering available for up to 16 nodes. - Storage optimized:
40 vCPUs, 80GB RAM, 80 TB HDD
- Compute optimized:
- Snowcone
2 CPUs, 4GB RAM, wired or wireless access USB-C power or battery
AWS OpsHub
Piece of software to install on PC or Mac etc. and gives the functionality for managing the Snow Family devices.

Amazon Managed Streaming for Apache Kafka (AWS MSK)
A fully managed service. Deployed in VPC, Multi-AZ (up to 3). Data is stored on EBS (Elastic Block Store) volumes.
In comparison with Kinesis you can create custom configurations:
- For ex. increase the message size limit from 1MB to 10MB
MSK security
Communication between Kafka brokers, as well as between Kafka broker and client may be configured to use TLS encryption. Data at rest stored on EBS is encrypted using KMS (Key Management Service).
Authentication and authorization:
- Mutual TLS (TLS for authentication), requires usage of Kafka ACLs (for authorization)
- SASL/SCRAM (username and password), requires usage of Kafka ACLs (for authorization)
- IAM Access Control – for both authentication (AuthN) and authorization (AuthZ)
Monitoring
CloudWatch metrics available:
- Basic monitoring – cluster and brokers metrics
- Enhanced monitoring – extra metrics on brokers
- Topic-level monitoring – extra topics metrics
Prometheus monitoring:
- Done using a port opened on the broker which allows to export cluster, brokers and topics metrics
- May use JMX Exporter for above metrics
- Or use Node Exporter for CPU and disk metrics
Broker logs can be delivered to:
- CloudWatch
- S3
- Kinesis Data Streams
Kafka Connect in AWS
Kafka Connect framework in AWS is called MSK Connect. If supports auto-scaling (for increasing/decreasing the workers count).
MSK Serverless
No cluster provisioning required! Only define the topics required and how many partitions per topic. Security model available is IAM Access Control.
